Big Data 02: MapReduce
1. Introduction of MapReduce
빅데이터에 대한 컴퓨팅은 여러 문제에 직면했는데, Distributing Computation(분산 컴퓨팅)이 어렵고, Distributed/Parallel(분산/병렬) 프로그래밍이 어렵다는 문제가 있었다.
MapReduce 알고리즘은 위 문제점들을 해결할 수 있는 모델이다.
구글이 개발하였으며, 자동으로 분산/병렬처리를 이용해 빅데이터를 다루는 효율적인 알고리즘이다.
더 단순하게 설명하면, 아래와 같다.
MapReduce는 병렬 프로그래밍 모델이며, map()과 reduce()함수를 이용해 빅데이터를 처리한다.
2. Single Node Architecture vs. Cluster Architecture
1) Single Node Arch.
보통은 컴퓨터 1대에 더 좋은 CPU, Disk를 꽂아 성능을 향상하는 Scale-Up 방식을 사용한다.
2) Cluster Arch.
구글의 웹페이지를 모두 읽는데 4달이 걸릴 만큼, 현재의 데이터 생태계는 굉장히 방대해졌기 때문에,
Linux 노드를 클러스터로 묶고, 이를 네트워크로 연결함으로써 해결한다.
3. Large-Scale Computing
- 어떻게 분산 컴퓨팅을 할 것인가?
- 어떻게 분산된 프로그램 작성을 쉽게 할 것인지?
- 쉽게 죽는 서버 문제를 어떻게 해결할 것인지?
- 네트워크를 통해 데이터를 복사 시에 시간에 매우 오래 걸리는 Network Bottleneck 문제가 발생
위와 같은 문제에 직면한 구글은 다음과 같은 아이디어를 제시하여 해결한다.
- Network Bottleneck 문제를 해결하기 위해 데이터 가까이로 연산을 가져오는 것
- 서버가 계속 다운되서 생기는 reliability 문제를 해결하기 위해 복제(copy)를 사용해 파일을 여러 번 저장하는 것
앞으로 다음과 같은 큰 두 가지 부분에 대해서 다룰 것이다.
1) Storage Infrastructure - File System
구글은 구글의 GFS를 썼고, 일반적으로는 Hadoop의 HDFS를 쓴다.
1) Programming Model
MapReduce
4. Storage Infrastructure - File System
앞서 다뤘듯이, Cluser Architecture기반의 노드는 자주 오류를 일으키고 다운되기 때문에,
데이터를 지속적으로 저장하는 방법에 대한 논의가 이뤄져 왔다.
그 해결 방안으로 DFS(Distributed File System)을 채택하였다.
Hadoop HDFS와 같이, global file namespace를 제공한다.
Client가 보통 100GB 이상에서 TB의 단위를 저장하는데, WORM(Write-Once-Read-Many) 방식을 사용한다.
데이터가 거의 업데이트 되지 않고, 일반적으로 데이터를 읽고 추가하는 유형의 데이터에 사용한다.
[Distributed File System의 일반적인 구성]
1) 데이터 노드(=청크 서버)
쉽게 말해서 일벌들이다. 빅데이터 기반의 파일을 64MB 혹은 128MB로 잘게 쪼갠 chunk가 저장되며,
각 chunk는 3 copy 방식을 사용한다. 즉, copy해서 총 동일한 파일을 3개 가지고 있으며, 의존성 문제를 해결하기 위해 보통 1개는 서버와 같은 렉에 1개는 서버와 다른 렉에 저장한다.
2) 마스터 노드
쉽게 말해서 여왕벌이다. 파일들이 어디에 저장되어 있는지에 대한 메타데이터를 저장한다.
여왕벌이 죽으면 일벌 전체가 다 죽는다.
마스터 노드가 죽으면 데이터 노드 전부가 죽기 때문에 초기에는 구현이 안 되었지만, 후의 DFS에서는 마스터 노드의 복제 노드가 등장한다.
3) 그렇다면, Client는 어떻게 접근을 하는가?(파일 접근을 위한 클라이언트 라이브러리)
데이터 노드를 찾기 위해서 먼저 마스터 노드에 질의한다.
그 다음, 데이터에 접근하기 위해 데이터 노드에 직접 연결한다.
데이터 노드(chunk server)는 복제 방식을 활용해 데이터의 Reliability를 높여줬을 뿐만 아니라,
compute server로서의 역할을 수행하여 데이터에 직접 연산을 가져오는 역할을 한다.
5. Programming Model: MapReduce
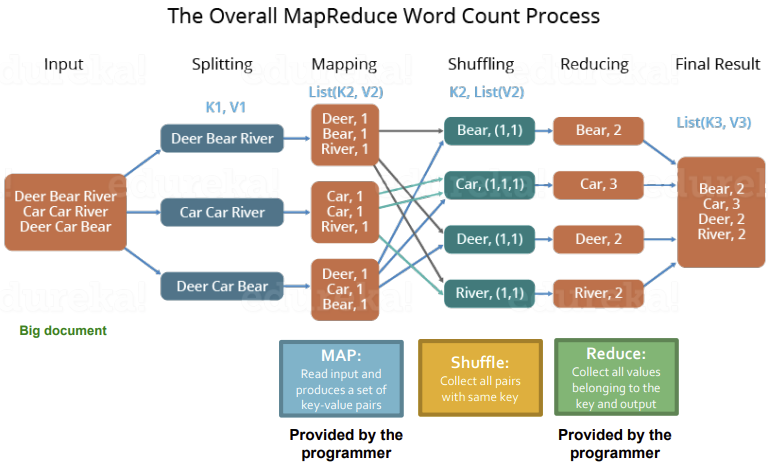
MapReduce의 설명 편의를 위해서 거대한 text document(eg. 1TB)에 각 단어가 얼마나 많이 등장하는지를 계산하는 Word Count 상황을 가정해보자.
문서의 한 줄을 읽어 중복되는 값을 제거하고 개수를 카운트하는 상황을 가정해보자.
각 줄에서 일어나는 word count는 다른 줄의 process에 영향을 미치지 않는다.(Parallelized)
[Process Overview]
- 각 줄의 텍스트 데이터를 순서대로 읽는다.
- Map 함수를 실행한다.
- Key를 통해 그룹화한다.
- Reduce 함수를 실행한다.
- 결과가 나온다.
여기서 미리 알아둘 중요한 특징들이 몇 개 있다.
Input 값이 key-value 쌍이라고 했는데, 한 줄씩 문장을 읽는 상황이면 사실 뭐가 key인지 잘 모른다.
key 값은 filename이며, value 값은 문장이다.