
[AI Red Teaming] AI 레드티밍이란? — 정의, 전통 보안과의 차이, 방법론
AI 레드티밍(AI Red Teaming)의 정의와 전통 보안 테스트와의 차이, 핵심 용어, 방법론, 주요 공격 벡터와 방어를 한 번에 정리합니다.
AI 레드티밍(AI Red Teaming)의 정의와 전통 보안 테스트와의 차이, 핵심 용어, 방법론, 주요 공격 벡터와 방어를 한 번에 정리합니다.

AI로 소프트웨어 취약점을 찾는 흐름 정리. Google Big Sleep이 SQLite 제로데이를 찾고 실제 악용을 막은 사례, LLM 퍼징·코드분석 원리와 한계.

LLM 기반 침투테스트(pentest) 정리. PentestGPT·자율 에이전트가 공격 체인을 짜는 원리와 효능, 환각·컨텍스트 한계, 권한·윤리 가드레일까지.

적대적 예제 정리. 미세 교란으로 모델을 오작동시키는 원리(FGSM), LLM의 적대적 접미사(GCG)로 탈옥하는 법, 적대적 학습·필터 방어까지.

멤버십 추론 공격(MIA) 정리. 특정 데이터가 학습셋에 있었는지 알아내는 원리, shadow model 기법, 프라이버시·저작권 위협과 차등 프라이버시 방어.

멀티에이전트·A2A(Agent2Agent) 보안 정리. 프롬프트 감염(LLM-to-LLM 전파), Agent Card 위장, 신뢰-권한 불일치 공격과 인증·격리·메시지 검증 방어.

모델 추출·탈취(model stealing) 공격 정리. API 쿼리로 가중치·구조를 복원하는 원리, $20로 상용 LLM 일부를 추출한 연구, rate limit·출력제한 방어.

LLM 가드레일 구축 가이드 — input/output/topical/retrieval rail, NeMo·Llama Guard·Guardrails AI 비교, 적용 시나리오와 한계.
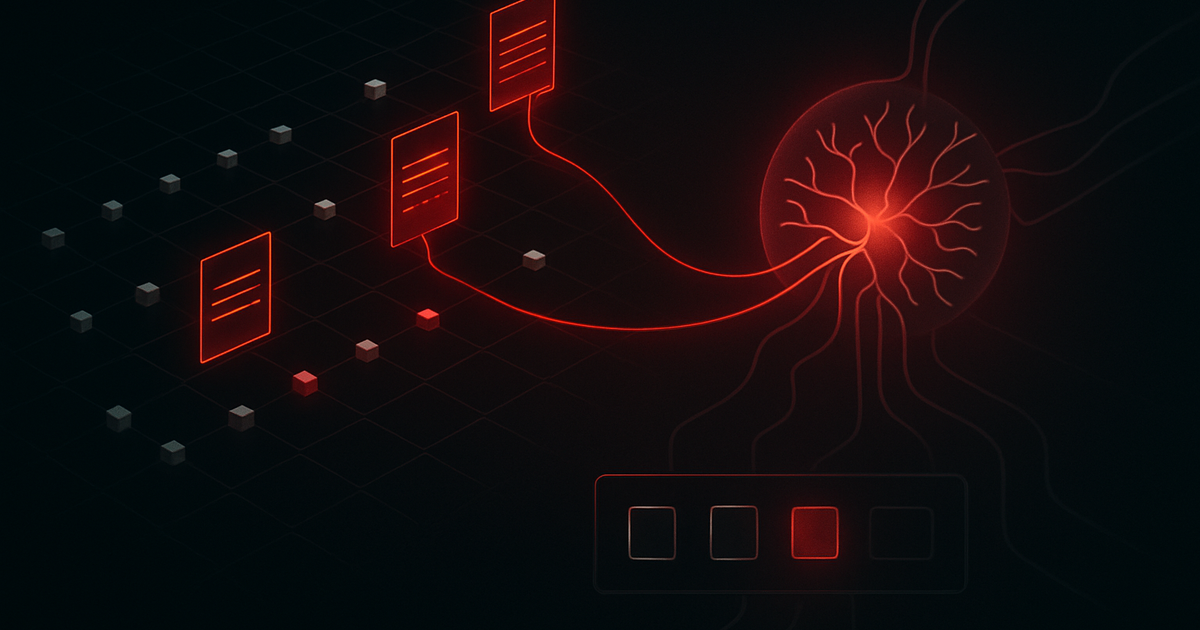
RAG 지식베이스 포이즈닝(PoisonedRAG) 공격 원리와 방어. 검색 문서가 공격표면이 되는 메커니즘, 5개 텍스트로 90% 성공한 연구, 출처검증·격리·리랭킹.

Microsoft PyRIT로 생성형 AI를 자동 레드팀하는 법. targets·converters·scorers·orchestrators·memory 구조와 단일·다회전 공격, garak과의 차이까지.