Computer Architecture 04: Processor(2) - Pipelining & Hazards
1. MIPS Pipeline
기본적으로 파이프라인 기법으로 실행(overlapping execution)하는 것이 성능 향상에 도움이 된다. (Throughput의 증가)
Piplelining Intro
N개의 task가 있다고 했을 때, 각 stage마다 걸리는 시간이 동일하다고 가정하면, k개의 stage가 존재한다고 했을 때, $Speedup =\frac{N}{\frac{N}{k}+(k-1)}$와 같이 표현할 수 있고, Non-Piplined에 비해 얼마나 빨라졌는지 계산할 수 있다. task가 굉장히 많아져 N을 무한대로 발산시키면, $\underset{N \to \infty}{\lim} = k$
결국 pipelining 기법을 통해 stage의 개수만큼 빨라지는 것을 확인할 수 있다.
이 사실을 바탕으로, MIPS processor는 Pipelining을 활용한다.
5개의 Stage로 구성되며, 구성은 다음과 같다.
- IF: Instruction Fetch (from mem)
- ID: Instruction Decode (& register read)
- EX: EXecute operation or calculate address
- MEM: access MEMory operand
- WB: Write result Back to reg

MIPS_Pipelining의 Performance 예시를 하나 보자.
예를 들어, Register Read/Write에 100ps가 소요되고,
다른 stage에서는 200ps가 소요된다면,
다음과 같은 표를 작성해 볼 수 있다.
| Instruction | IF | ID | EX | MEM | WB | Total Time |
|---|---|---|---|---|---|---|
| lw | 200ps | 100ps | 200ps | 200ps | 100ps | 800ps |
| sw | 200ps | 100ps | 200ps | 200ps | x | 700ps |
| R-format | 200ps | 100ps | 200ps | x | 100ps | 600ps |
| beq | 200ps | 100ps | 200ps | x | x | 500ps |
Compare Performance "Single-cycle datapath" vs. "Pipeline datapath"
1) Single-cyle datapath
1 cycle에 1개의 instruction만 실행한다.
따라서, $T_c = 800ps$ 이다.
2) Pipeline datapath
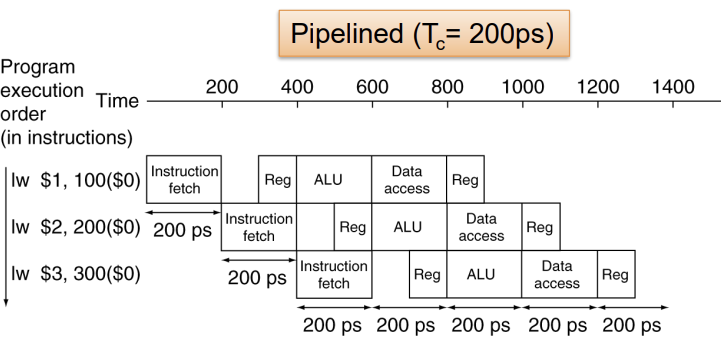
위 그림에서와 같이, 1 cycle에 1개의 stage가 실행되기 때문에, $T_c = 200ps$ 이다.(instruction 종류와 stage에 따라 가장 오래걸리는 시간으로 설정한다.)
앞서 Pipelining Intro에서 살펴본 것과는 다르게, 중간에 시간 낭비하는 구간이 생기며, 각 stage당 걸리는 시간이 다르다.
Speedup(Pipeline 방식이 몇 배 빠른지)값을 계산해보면 다음과 같다.
\(Speedup = \underset{N \to \infty}{\lim} \frac{800N}{800+200N} = 4\) (여기서 N은 instruction의 개수를 말한다)
즉, Pipeline 방식이 4배 더 빠른 것을 확인할 수 있다.
뭔가 이상한 점을 눈치채야 한다. 앞서 Pipelining Intro에서 살펴본 예시에서는, 각 stage에 동일한 시간을 소모하기 때문에 M개의 stage가 있다면 M배 더 빠른 Pipeline이 된다. 하지만, 위 예시처럼 중간에 시간 소모가 생기는 부분, 즉, 각 stage당 소모하는 시간이 다르게 되면, speedup은 덜 증가한다.(모든 stage가 balanced인 상황보다 덜 빠르다는 말이다.)
그래서, 5개의 stage임에도 불구하고, 4배 더 빨라졌다.
따라서, Pipelining의 특징을 정리하면 다음과 같다.
- Speedup이 되지만, 온전히 throughput 증가의 결과물이다.
- instruction 하나가 만들어내는 Latency는 줄어들지 않는다. 오히려 증가할 수도 있다.
- MIPS ISA는 모두 32bit의 instruction으로 설계되고, 매우 적고 규칙적인 instruction format을 제공하며, load/store addressing, memory 피연산자의 정렬을 통해 Pipelining을 제공한다.
2. Hazards
Hazards란, 다음 cycle에 일어날 instruction이 시작하는 것을 막는 상황을 말한다. 즉, processor의 연산을 느리게 하고, pipelining을 방해하는 주요 원인이며, 크게 3가지 상황으로 구분한다.
- Structure Hazards
- Data Hazards - Data Hazard & Load-Use Data Hazard
- Control Hazards
하나씩 살펴보도록 하자.
Structure Hazards
resource 사용에 대해 confliction이 발생하면 일어나는 Hazards로, HW 구조적 Hazards이다.
MIPS Pipeline에서 single memory를 사용한다고 해보자.
lw나 sw같은 instruction은 메모리에 접근해 data access를 한다.
만약, 과거 lw instruction이 MEM stage에 있어 memory에 접근해 data를 불러오는 작업을 수행하면서, 현재 lw instruction이 IF stage에 있어 instruction이 담긴 memory에 접근해 instruction fetch를 진행한다면, memory라는 자원이 1개만 존재하기 때문에 동시에 여러 stage에서 접근하는 것이 불가능하고 둘 중 하나만 점유할 수 있다.(한 놈은 양보를 해야 함)
이 때, 자연스럽게 stall이 발생할 수 밖에 없다. (bubble이라고도 함)
stall이란 ‘지연’이라는 의미로 해석하는 것이 좋을 것 같고, Hazards 등의 이유로 아무 것도 하지 않고, 1개 이상의 cycle을 기다리는 것을 의미한다.
이러한 구조적 문제를 해결하기 위해서, instruction 메모리와 data 메모리를 따로 분리하여 해결한다.
Data Hazards
An instruction depends on completion of data access by a previous instruction이라고 책에 설명되어 있는데, 쉽게 설명하면, 미래 instruction이 과거 instruction의 결과를 사용할 때 발생하는 Hazard이다.
add $s0, $t0, $t1
sub $t2, $s0, $t3
다음과 같은 MIPS 코드가 있다고 하자.
add instruction 실행 시, ID->EX에서 $t0, $t1을 읽어 들이고, EX->MEM에서 ($t0+$t1)이 계산된다. 그러면, $s0에 저장되는 건 언제일까? 바로, WB 단계에서 $s0에 ($t0+$t1)과 동일한 값이 write된다.
sub instruction 실행 시, ID->EX에서 $s0, $t3를 읽어 들인다. 이때, $s0는 무슨 값인가? ($t0+$t1) 이전의 어떤 값일 것이다. 즉, 쓰레기 값으로 연산을 하게 되는 상황이 발생한다.
1 cycle을 낭비하는 Stall(=Bubble)로 해결할 수 있지만, 너무 비효율적이다. 따라서, Forwarding(=Bypassing)을 통해 해결한다.
Forwarding
결과값이 저장(write)되기 전에, 연산된 결과를 다른 instruction에 사용하는 것이다.
추가적으로, datapath connection이 필요한데, Pipeline의 확장된 register, Datapath, control 등은 이 게시글의 3. MIPS Pipelined Datapath w/ Control 파트에서 자세히 알아볼 예정이다.
Load-Use Data Hazard
추가로, 위의 data hazard도 있다. 불가피하게 Stall을 해야 하는 Hazard로, 주로 lw 뒤에 R-format 연산이 나오는 경우인데, 이때는 1 cycle을 버리고, Forwarding한다.
하지만, Code Scheduling을 통해서 Stall을 하지 않게 만들 수 있다.
예를 들어,
lw $t1, 0($t0)
lw $t2, 4($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)
lw $t4, 8($t0)
add $t5, $t1, $t4
sw $t5, 16($t0)
위와 같은 코드 구성은 lw $t2, 4($t0)에서 add $t3, $t1, $t2로 넘어갈 때와 lw $t4, 8($t0)에서 add $t5, $t1, $t4로 넘어갈 때 총 2회의 stall이 일어난다.
instruction cycles 계산하는 방법은 (number_of_instructions)+(number_of_stage -1)+(number_of_stall)이다.
따라서, 13 cycles 이 걸린다.
lw $t1, 0($t0)
lw $t2, 4($t0)
lw $t4, 8($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)
add $t5, $t1, $t4
sw $t5, 16($t0)
하지만, 다음과 같이 code reordering을 한 경우, load-use data hazard는 발생하지 않게 되어 2회의 stall은 발생하지 않게 된다. 따라서, 총 11 cycles이 소요된다.
Control Hazards
beq, bne(if/else, switch, for, .. in C)같은 branch instruction은 flow of control(control의 흐름을 결정한다. 프로그램의 흐름을 결정한다.)
그 다음 instruction을 fetching하는 작업은 branch 조건에 대한 결과에 의존하기 때문에 항상 정확한 instruction을 fetch할 수 없다.
따라서, Control Hazards는 branching 상황에 일어나고, 1 cycle을 낭비해야 한다. (Stall)
다음 instruction이 fetch되기 전에 branch outcome이 결정될 때까지 기다려야 한다는 것이다.
하지만, branch prediction으로 어느 정도 해결할 수 있다.
prediction이 맞으면 Stall 없이 cycle이 진행되며, prediction이 틀렸을 때 stall을 하게 된다. branch prediction은 2가지 방식이 존재한다.
1) Static branch prediction
typical branch behavior에 기반한다. 예를 들어, for와 같은 loop문에서 조건을 통해 branch 판단할 때, loop문 내의 코드 실행을 일반적으로 기대하지, loop문의 탈출을 기대하고 for문을 작성하지는 않는다. 즉, loop나 if문 branch 상황에서 backward branches(조건에 맞는 loop문 내의 코드, if문 내의 코드를 실행)을 예측하는 것이 일반적이다. 따라서, 이러한 prediction을 바탕으로 한 것이 static branch prediction이다.
2) Dynamic branch prediction
Hardware를 통해 branch behavior를 결정한다. 실제로 branch 되는 history를 저장해서 미래의 behavior를 예측한다.(깊게 다루지는 않는다.)
3. MIPS Pipelined Datapath w/ Control
이 게시글의 썸네일이 이번 파트의 전부이다.
MIPS에서는 Pipelining을 위해 Pipeline registers를 도입한다.
Pipeline Operation을 살펴보는 두 가지 다이어그램이 있는데,
하나는 single-clock-cycle pipeline diagram이고, 다른 하나는 multi-clock-cycle pipeline diagram이다.
single이 1 cycle 내에서 어떻게 pipelining이 일어나는지를 알기에 편하고, 어떤 resource를 사용한 것인지를 나타내기에 좋다. 반대로 multi는 시간에 따라서 operation에 대한 그래프 표현이 가능하기 때문에 장단점이 있다.
책에서는 lw/sw 에 대해서 single-clock-cycle pipeline diagram을 먼저 다룬다.
Load/Store in single-cycle pipeline diagram
lw $B C($A)인 MIPS 코드를 실행하는 상황을 가정해보자.
- IF stage
clock이 한번 tick할 때, 32bit의 기계어가 들어온다. Instruction Memory에서는 그것을 그냥 읽고(Read), lw나 sw instruction에 대한 명령어를 가져온다(fetching). 후술하겠지만, instruction cache 참조를 하기도 한다. 불러온 명령어는 IF/ID register에 저장된다(Write). 뿐만 아니라, 다음 instruction 실행을 위해 PC+4도 이때 수행된다. 이 값도 IF/ID register에 저장된다. 추가로, Mux로도 값이 이동한다.(EX에서 연산한 I-format instruction에 의해 이동하는 주소(PC+4+4*address)와 MEM에서 연산된 branch 관련 control signal 값이 계산되면 처리한다.)
IF/ID.IR <- IMEM[PC];
PC <- PC+4; - ID stage
그 다음 clock이 한번 더 tick하면, IF/ID register에 저장된 instruction memory를 거친 32bit 값(fetch된 instruction)과 (PC+4)를 읽는다(READ). 이후 과정은 single-cycle-datapath와 동일하다. 하지만, Write Register와 Write Data 부분이 조금 변경된다. (cf. EX stage에서 MUX와 RegDst Control Signal을 통해 MEM, WB stage를 거쳐 Write Reg, Write Data가 일어난다.) 이 모든 과정이 끝나면, (PC+4)값은 그대로 저장되고, $A에 대한 정보와 Sign Extend된 정보는 ID/EX register에 저장된다.
ID/EX.A <- Reg[IF/ID.IR[25:21]];
ID/EX.IMM <- sign-extend(IF/ID.IR[15:0]); - EX stage
clock이 한번 더 tick하면, ID/EX register에 저장된 $A 주소값과 Sign-extend된 값을 읽어온다(READ). 전 과정은 single-cycle-datapath와 동일하다. (cf. I-format instruction의 주소 변환이 EX stage에서 일어난다.) 연산된 값은 EX/MEM register에 저장된다.
EX/MEM.AR <- ID/EX.A + ID/EX.IMM; - MEM stage
clock이 한번 더 tick하면, ($A+C)값을 EX/MEM register에서 읽어오고, Data memory에서 해당 주소에 위치한 데이터를 읽는다. 그리고, 그 값을 MEM/WB register에 저장한다.
MEM/WB.LR <- DMEM[EX/MEM.AR]; - WB stage
마지막으로 한번 더 clock이 tick하면, MEM/WB register에 저장된 data가 register로 다시 돌아와 write 되어야 하는데, 이때 버그가 발생한다. $B(aka. rt)에 대한 문제이다. 레지스터에 값을 작성할 때 rt 필드에 값을 써줘야 하는데, 이미 시간이 지난 시점에서 ID stage는 미래 시점의 MIPS 코드가 실행되고 있을 것이고, 이때의 IF/ID register에서 읽어오는 값은 동일한 instruction이 아니다. 따라서,wrong register number, 잘못된 reg# 참조, 즉, 미래 시점의 다른 MIPS 코드의 register number를 참조하기 때문에 bug가 발생한다.
이를 해결하기위해, rt에 대한 정보는 매 stage가 진행될 때마다, 같이 Pipeline register를 통해 넘겨준다.
- Store 상황을 예를 추가로 들어보자. -> sw $B C($A)
IF/ID stage는 lw와 유사해서 설명은 생략한다.
3) EX
single-cycle-datapath와 동일하다. ID/EX register에 저장된 C, $B, $A를 불러와 circuit상에서 연산한다. 연산 결과는 EX/MEM reg에 저장된다.
4) MEM
single-cycle-datapath와 동일하다. Data Memory에서 $A+C 주소를 참조하고, $B에 위치한 Data를 읽어 sw 작업을 수행한다.
5) WB
=> No operation, 아무 연산도 일어나지 않는다.
Multi-Cycle Pipeline Diagram
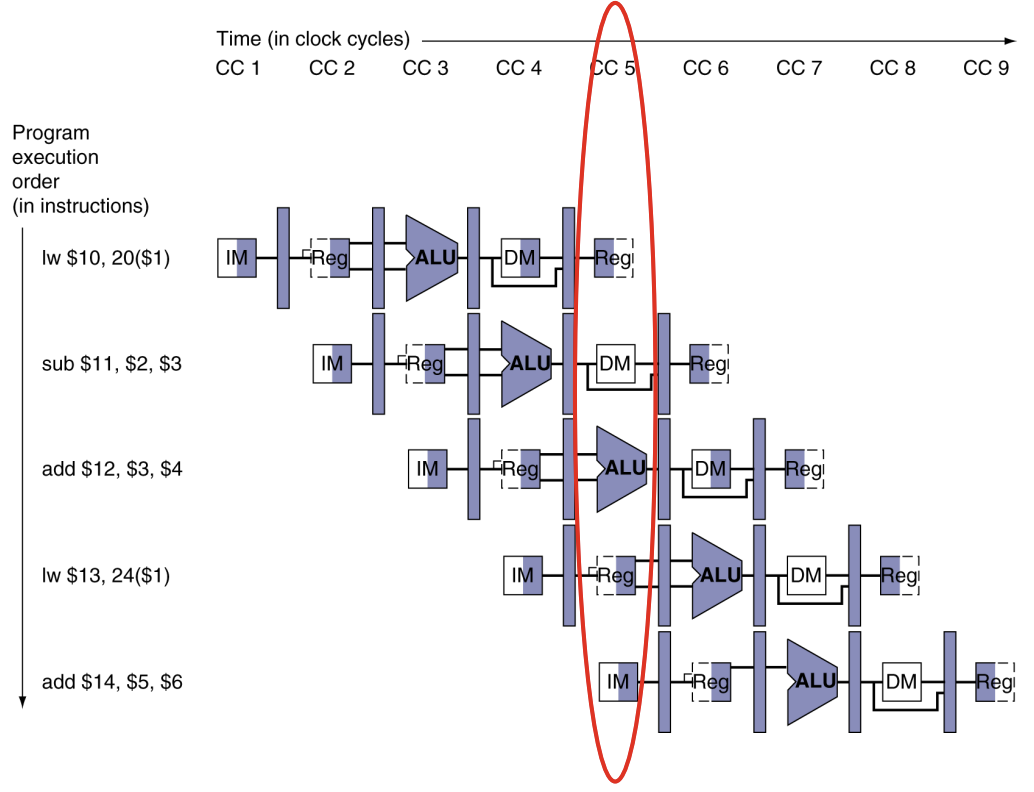
위 그림과 같이, 시간이 지나면 지날수록 위에서 아래로 새로운 instructions이 진행되고, 각 stage마다 서로 다른 instruction이 수행된다.
빨간색 부분을 시계 방향으로 90도 회전하면, 아래 그림과 같이 표현된다.
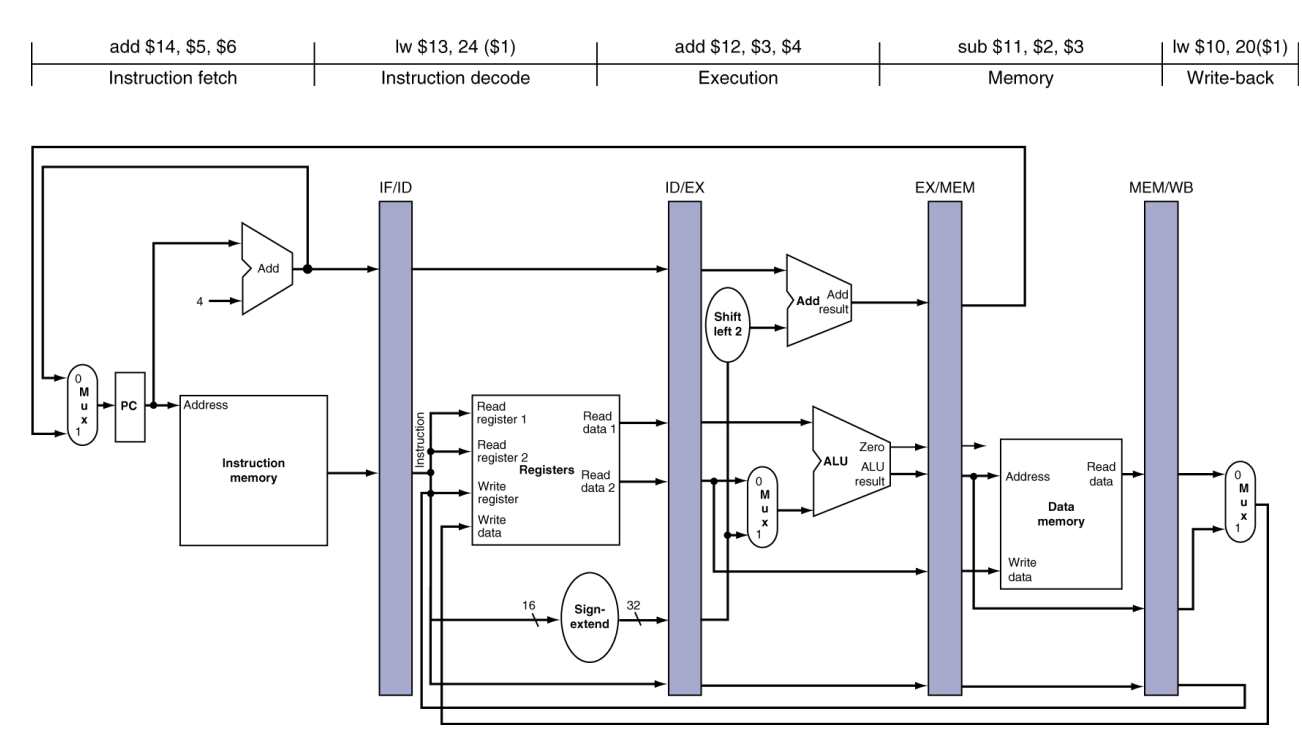
Control Signals
Control Signal은 instruction으로부터 유래되기 때문에, 각 register에 WB, MEM, EX와 관련된 control 값들이 저장된다.
Pipelined Datapath with Control
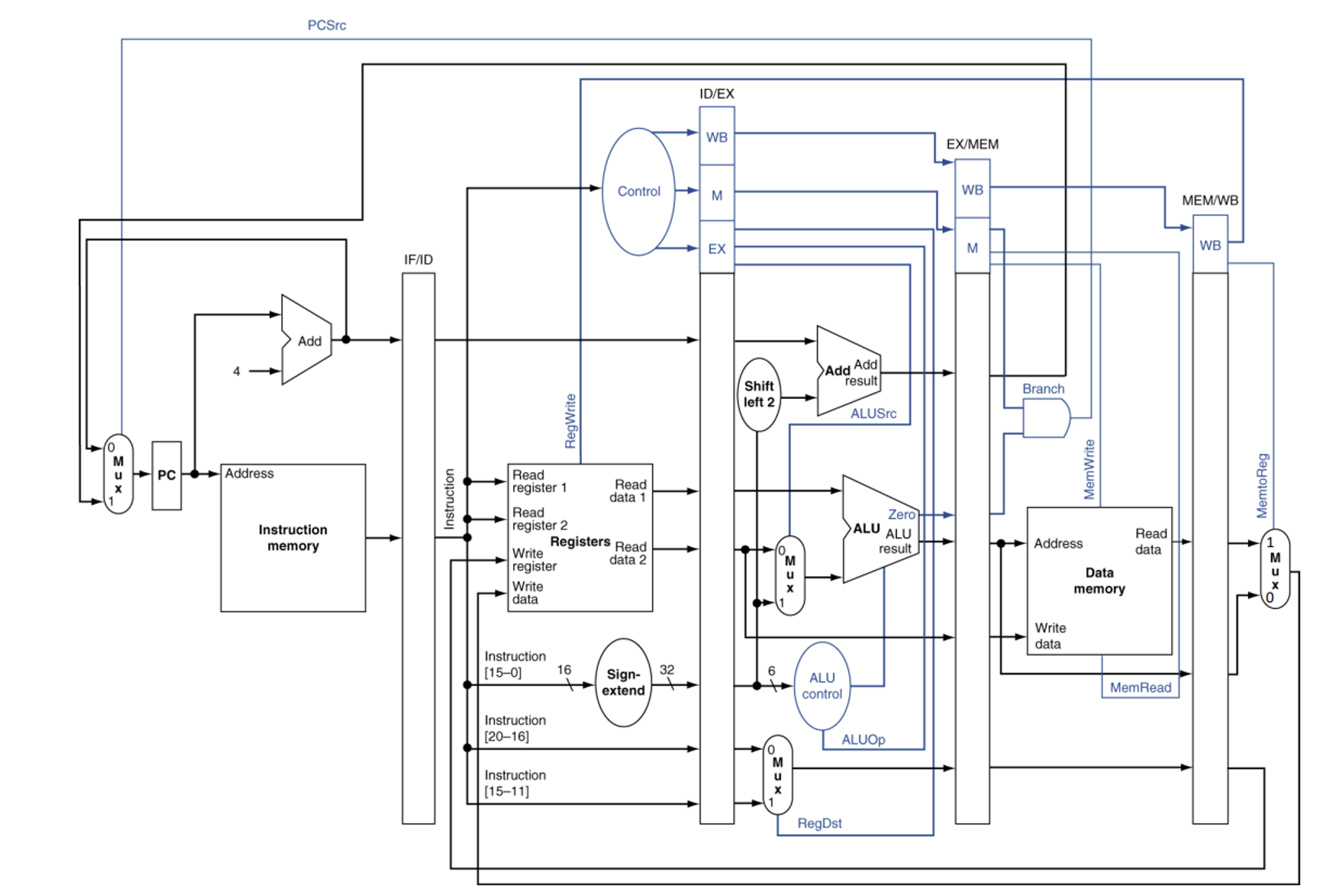
최종본이다.
4. Detection the need to Forward
ALU OPs를 수행할 때, Forwarding은 언제 일어날까?
- Previous rd == Current rs or rt
- Previous Previous rd == Current rs or rt
단 두 줄로 정리하면 위와 같다.
조금 더 자세히 정리해보자.
1a. EX/MEM.RegisterRd = ID/EX.RegisterRs
1b. EX/MEM.RegisterRd = ID/EX.RegisterRt
2a. MEM/WB.RegisterRd = ID/EX.RegisterRs
2b. MEM/WB.RegisterRd = ID/EX.RegisterRt
우항이 Current이고, 좌항이 Previous (or Previous Previous)를 뜻한다.
또한, 다음 조건을 만족시켜야 한다.
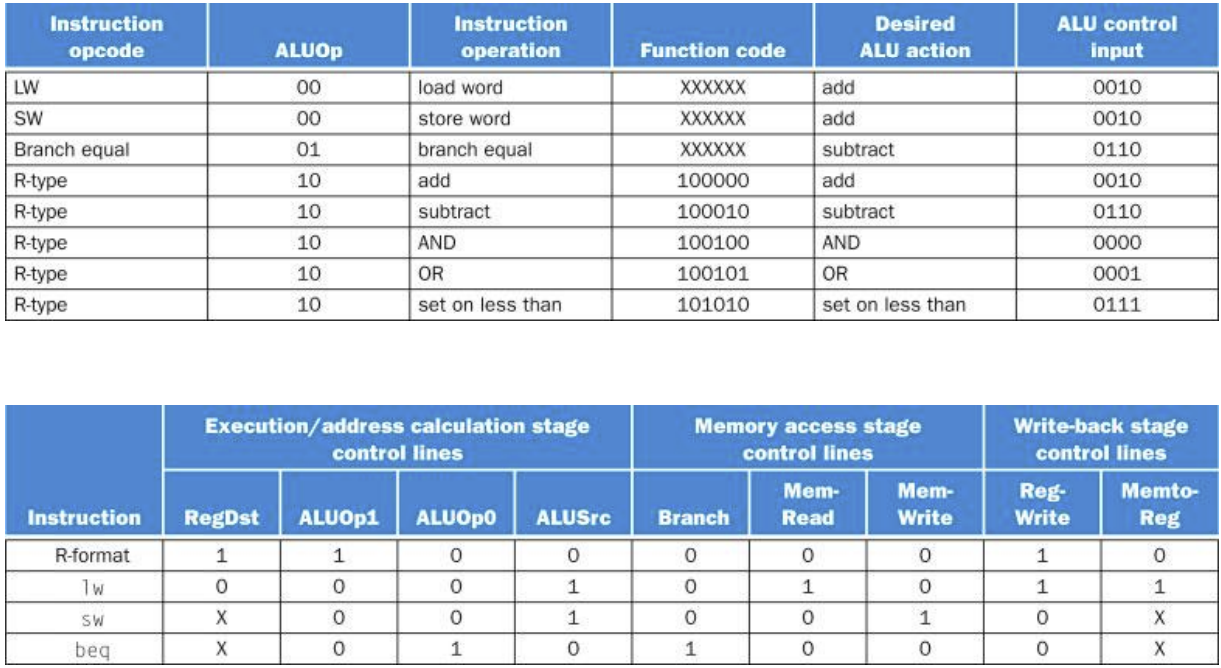
1) 1의 경우 EX/MEM.RegWrite == 1, 2의 경우 MEM/WB.RegWrite == 1 (Forwarding instruction이 reg에 write할 때만!)
2) EX/MEM.RegisterRd != 0, MEM/WB.RegisterRd != 0 (Rd값이 $zero면 안된다.)
추가로, 앞으로 1번과 같은 상황을 EX Hazard, 2번과 같은 상황을 MEM Hazard라고 부를 것이다.
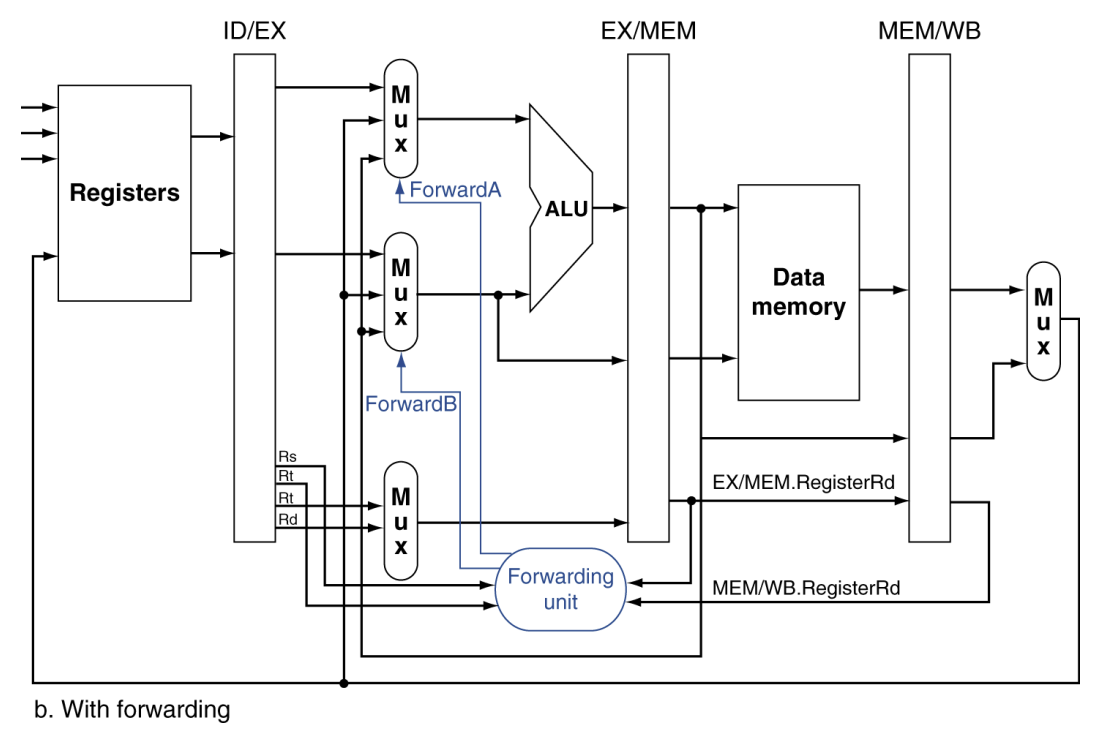
이해하는데 도움이 될 것이다.
Double Data Hazard
다음과 같은 MIPS 코드를 살펴보자.
add $1, $1, $2
add $1, $1, $3
add $1, $1, $4
Data Hazard가 두 번 연속으로 일어나서, 3번째 코드의 rs인 ($1)은 previous code의 rd를 포워딩받아야할지, previous previous code의 rd를 포워딩받아야할지 선택해야한다.
너무 당연하지만, 최근의 값을 forwarding 받는 게 맞다. 즉, previous rd를 포워딩받아야 한다.(If both hazards occur, we have to user the most recent value.)
Only forward if EX hazard condition isn’t true
- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0) and NOT ( EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs) ) and (MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01
- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0) and NOT ( EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt) ) and (MEM/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01
Load-Use Data Hazard Detection
Load-use Data Hazard는 다음과 같은 때에 일어난다.
ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt))
즉, previous Rt가 current Rs 또는 Rt와 같고, MemRead Signal이 있으면, Load-use hazard를 detect한 것이다.
이때, stall하고 bubble insert한다. (== waste 1 cycle)
How to stall the pipeline
- ID/EX register의 control 값을 모두 0으로 강제로 바꾼다.
EX, MEM, WB은 nop을 한다. (nop: no-operation)
데이터는 읽고 쓰는 대신, EX, MEM, WB stage가 bubble로 채워진다.
그러고 동일한 instruction을 다시 한번 더 실행한다. - PC의 업데이트와 IF/ID register의 업데이트를 막는다.
ID를 한번 더 수행, 그 다음 instruction도 IF가 한번 더 수행된다.
자연스럽게 LW에 대해서 MEM stage가 read data하도록 만든다. (포워딩은 EX stage에서 일어나기 때문!)
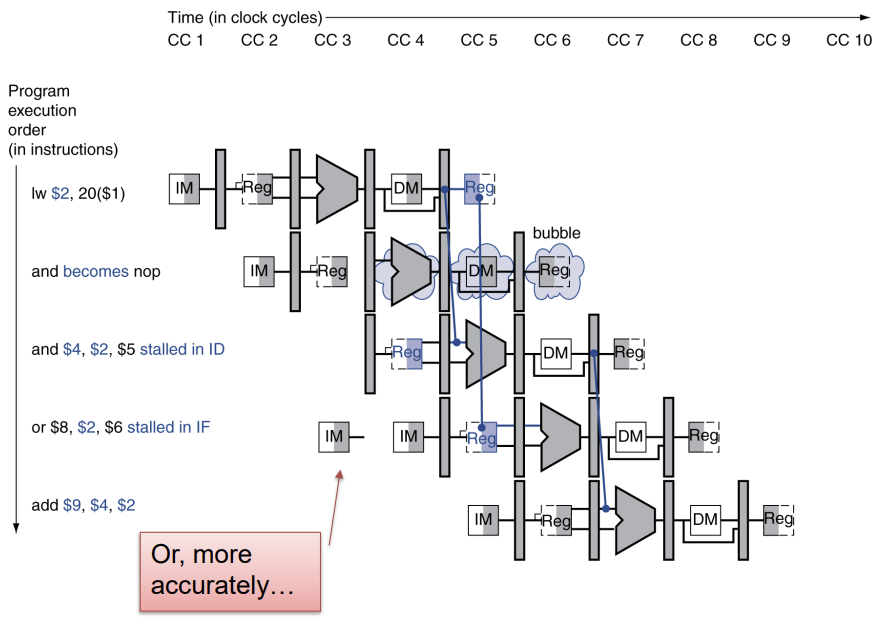
위 예시가 이해되어야 한다.
5. Stalls & Performance
Stalls은 일반적으로 성능을 저하시키지만, 정확한 결과를 만든다.
당연히 컴파일러는 hazards와 stalls을 피하기 위해 code를 재정렬할 수 있어야 한다.
ILP(Instruction-Level Parallelism)
Pipellining은 여러 instruction을 병렬로 실행하는 것으로,
ILP를 높이기 위해서는 다음과 같은 방법을 사용한다.
- Deeper Pipeline
파이프라인의 깊이를 증가시켜 더 많은 명령얻릉르 중첩시키는 방법으로, stage당 일이 줄어들고, clock cycle이 더 짧아져 성능이 좋아진다. - Multiple issue
pipeline stages를 복제해서 여러 개의 pipeline을 만드는 방법이다.
이로 인해서, 1 clock cycle에 여러 개의 instruction을 동시에 실행할 수 있다.
즉,CPI < 1일 수 있다는 것이다. 이때는 IPC(Instruction Per Cycle)을 사용한다.
하지만, 실제로 의존성이 발생해서 그렇게 빨라지지 못한다. - Loop Unrolling
loop body를 복제하는 방법이다.
branching 자체가 overhead가 크기 때문에, 컴파일러가 자동으로 for문을 통해 10번 실행된다면, 단순하게 코드를 10번 복붙하는 방법으로 ILP를 증가시킨다.
Power Efficiency
dynamic scheduling과 speculations이 복잡해짐에 따라 power가 필요하다.
따라서, multiple simpler cores가 더 좋은 성능을 보인다. (Power 측면)