Computer Architecture 05: Cache
1. Memory Hierachy & Disks
목표: 가장 빠른 메모리 속도와 함께, 가장 저렴한 메모리 크기를 제공하는 것
메모리는 위와 같은 목표를 가지고 설계되어야 한다. 하지만, 단일 메모리만으로 이를 만족시킬 수는 없다. cache의 기반이 되는 SRAM은 매우 빠르지만 굉장히 비싸고, 크기가 작으며, HDD의 기반이 되는 마그네틱 디스크나 RAM의 기반이 되는 DRAM의 경우, 훨씬 느리고 크기도 크지만, 값이 싸다.
프로세서가 데이터를 불러오는데 발생하는 bottleneck을 최소화하고, 빠르면서 가장 저렴한 메모리를 제공하기 위해 Memory는 계층 구조로 구성된다.
Locality
- Temporal locality
최근에 접근한 주소는 곧 다시 참조되는 특성이다.
시간과 관련된 지역성으로, Loop에서의 instruction이나 induction variable이 이에 해당한다.
(cf. induction variable: for 문에서 증가하는 i와 같은 변수를 의미한다.) - Spatial locality
공간과 관련된 지역성으로, 참조된 주소 근처의 주소가 참조될 가능성이 높은 특성을 말한다.
배열 데이터 등이 이에 해당하는 예시이다.
이러한 지역성을 잘 구현해 놓은 모델이 Memory Hierachy(메모리 계층 구조)이다.
- 가장 낮은 레벨(HDD, SDD)에 모든 데이터를 저장한다.
- 디스크에서 더 작은 DRAM(e.g. 메인 메모리)으로 최근에 접근한, 또는 가까운 데이터를 복사한다.
- DRAM에서 더 작은 SRAM(e.g. CPU에 부착된 Cache memory)으로 더 최근에 접근한, 또는 더 가까운 데이터를 복사한다.
여기서 정리할 수 있는 메모리 계층 구조의 특징이 몇 가지 있다.
- 데이터는 항상 인접한 두 레벨에서만 복사되어진다.
- 가장 낮은 레벨의 메모리는 모든 데이터를 가지고 있다.
- 상위 레벨 (Lv. 1, Lv. 2, …)에 존재하는 무조건 하위 레벨에 존재한다.
- CPU와의 거리 증가는 곧 접근 시간의 증가를 의미한다. 예를 들어, 캐시와 같은 Lv 1 정도의 메모리라고 하면, 1 clock cycle에 접근이 가능하지만, 디스크에 존재하는 데이터에 접그하려면 수천, 수만 cycle이 필요하다.
Hit & Miss
Block(=Line)이란, 메모리 계층 구조에서 복사하는 단위를 의미하며, 여러 개의 words로 구성된다.
Hit란, 접근한 데이터가 상위 레벨에 존재하는 경우를 의미하며, 해당 레벨에 존재하는 데이터를 복사한다.
반대로 Miss란, 접근한 데이터가 상위 레벨에 존재하지 않는 경우를 의미하며, 데이터 접근을 위해 하위 레벨에 접근하여 데이터를 상위 레벨로 복사해야 한다.
Hit ratio는 총 접근한 데이터 중 hit인 비율을 의미하고, Miss ratio는 이 반대를 의미하며, 1-(hit ratio)로도 나타낼 수 있다.
Memory Technology
- SRAM(Static RAM) 보통은 프로세서 내에 존재하는 캐시가 이에 해당하며,
하나의 IC(집적회로)에 6~8 개의 트랜지스터를 사용하여 데이터(=1bit)를 저장한다.
매우 빠르고, 매우 비싸다. - DRAM(Dynamic RAM)
보통은 메인 메로리가 이에 해당한다.
축전기(capacitor) 내에 전기 신호를 저장함으로써 데이터를 저장하며, 1bit 저장에 하나의 트랜지스터를 활용한다.
주기적으로 refresh해야 하는데, contents를 읽고 다시 써야하며, ‘row’ 단위로 실행되기 때문이다.
SDRAM(Synchronous DRAM): clock과 동기화되어 대역폭이 향상된 DRAM
e.g. DDRAM: 1 clock에 데이터를 두 번 복사하는 SRAM이다. - Flask Memory
디스크보다 100~1000배 빠른 비휘발성 반도체 저장 공간으로, 더 작고, 더 적은 전력 소모가 일어나며, 더 튼튼하다(robust).
하지만, 디스크에 비해 동일 용량 당 값이 더 나간다.
NOR Flash, NAND Flash 메모리가 있다.
가장 큰 단점은 1000번 정도 데이터에 접근(read/write)하면 Flash bit는 손상되는 것이다.(Flash bits wears out after 1000’s of accesses)
따라서, direct RAM이나 dish 대체는 불가능하다. - Magnetic Disk
HDD가 이에 해당한다. 매우 느리다.
위의 메모리들과 다르게 물리적인 저장 원리를 가지고 있다.
실린더 내에 disk platter들이 있고, 각 플래터에는 track와 track 내에 sector라는 단위로 데이터가 저장된다.
디스크 암(arm)을 통해 적절한 플래터, 트랙, 섹터를 찾아 정보에 접근한다.
각 sector는 sector ID, 데이터(보통 512 바이트, 4096 바이트로 구성), ECC, 동기화 필드 및 갭이 존재하며,
각 sector 접근 시 Queuing delay, Seek, Rotational latency, Data transfer, Controller overhead가 접근 속도에 관여한다.
2. Cache Memory
Cache 설계 시 주목해야 할 부분
- 데이터가 캐시에 존재하는지 알 수 있는 방법
- 캐시의 어느 부분을 봐야 하고, 어디다 데이터를 두어야 하는지
1) Direct-mapped 2) Fully Associative 3) M-way Set Associative
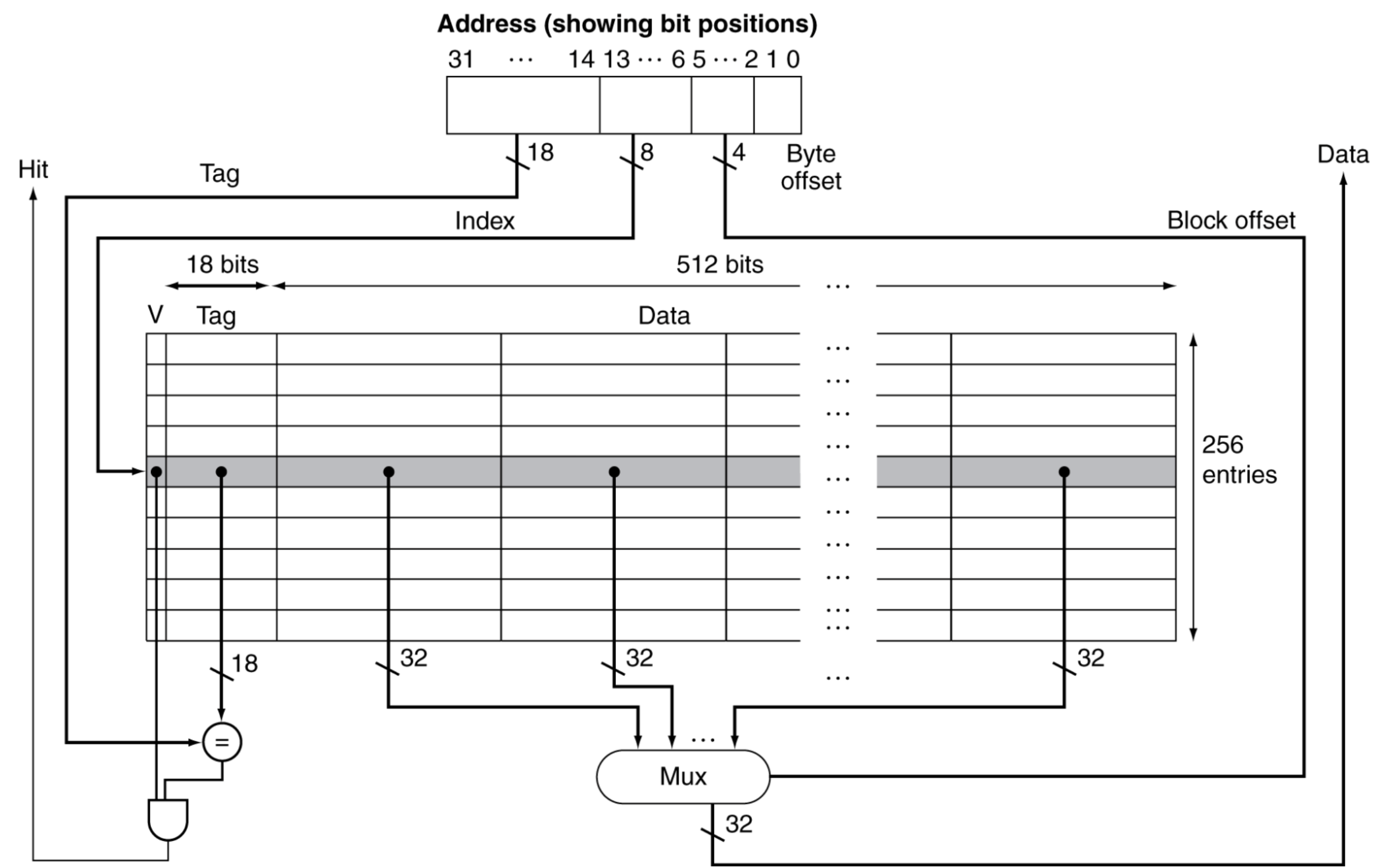
- Direct-Mapped Cache
캐시에 저장될 위치, 캐시에서 데이터를 확인할 위치는메모리 주소에 의해 결정된다.
이때, Direct-Mapped 방식은 한 가지 선택지 밖에 주어지지 않는다.
Block이란, 메모리 계층 구조에서복사하는 단위를 의미한다.
(Block address) modulo (number of blocks in cache) = output
만약 캐시에 8개의 block이 존재한다면, 000~111까지 8개의 block이 있고,
메모리 주소가 00001인 경우 8의 modulo 연산인 001에 해당하는 block에 데이터를 불러와 저장한다.
low-order address bits를 사용하고, block의 단위는 2의 거듭제곱 꼴이다.
여기서 문제는, 01101인 메모리 주소를 찾고 싶은데, 캐시의 101을 보았을 때, 참조하는 메모리 주소가 00101인지, 01101인지 헷갈린다는 것이다.
그래서 등장한 것이 Tag와 Valid Bit 이다.- Tag: 데이터 뿐만 아니라 block address까지 저장해야 하므로 등장한 것, 오로지 high-order bits 만 필요하다.
예를 들어, 위의 01101 예시에서, 01만 저장해도 되는 것과 같다. - Valid bit: 초기값은 0이고, 해당 위치에 데이터가 존재하면 1, 존재하지 않으면 0이다.
- Tag: 데이터 뿐만 아니라 block address까지 저장해야 하므로 등장한 것, 오로지 high-order bits 만 필요하다.
메모리 주소 = Tags + 캐시 블록 인덱스 + offset(2bytes)
3. Cache Performance
Cache Read Misses
만약 cache hit라면, CPU는 정상적으로 진행한다.
만약 cache miss라면,
- CPU 파이프라인에서 Stall 함
- 다음 메모리 계층의 블록을 fetch함
메인 메모리가 READ를 수행하도록 하고, 데이터에 접근을 완료하도록 메모리를 대기시킨다.
data, tag, valid bit를 포함하여 캐시 진입점에 내용을 쓴다. - 캐시 접근 재시작
instrcution cache가 miss 난 경우, 원래 PC 값(PC-4)로 돌아가서 instruction fetch를 재시작
data cache가 miss난 경우, data access를 완료시킨다.
Cache Write Misses
READ보다 조금 더 복잡하다.
data-write가 hit라면, 그냥 캐시에 block 정보를 업데이트하면 된다.
하지만, sw와 같이, 캐시에 무언가를 write 해야 하는 상황이라면, 메모리와 캐시에 가지고 있는 정보가 다른, inconsistency한 상황이 발생하게 된다.
해결 방법 1) Write-Through
캐시와 메모리를 항상 동시에 업데이트 하는 방법이다. 일단 캐시에 먼저 쓰고, 동일한 내용을 메모리에 작성한다.
매우 심플해서 좋지만, write 시간이 매우 길어진다.
따라서, Write buffer 방식을 대안으로 사용한다.
Write buffer 방식은 버퍼를 두고 한꺼번에 flush하는 방식으로, C언어에서 buffer flush하는 과정과 동일한 원리이다.
해결 방법 2) Write-Back
캐시만 업데이트를 진행하고, replace 되어질 때(=다른 메모리 주소에 접근할 때) 메모리에 수정된 블록을 write한다.
보통은 더 빠르지만 구현이 매우 어렵고 복잡하다.
만약 write miss가 일어나면, 메모리에서 캐시로 fetch를 해야 할까?
Write-Through 방식이라면, allocate on miss(=fetch the block) 와 write around(don’t fetch the block) 방식이 있다.
Wrtie-Back 방식이라면, block을 보통 fetch한다.
Cache Performance
CPU time = CPU 실행 시간 + Memory-stall time